sort – простая и очень полезная команда, которая меняет порядок строк в текстовом файле, то есть осуществляет их сортировку по алфавиту или в соответствии с числовыми значениями. По умолчанию правила сортировки следующие:
- строки, начинающиеся с цифр, выводятся раньше строк, начинающихся с букв;
- строки, начинающиеся с букв, выводятся в алфавитном порядке;
- строки, начинающиеся со строчных букв, выводятся раньше строк, начинающихся с таких же заглавных.
Правила сортировки можно изменять при помощи опций. Мы рассмотрим их ниже.
Синтаксис
Основной синтаксис команды следующий
sort [ОПЦИЯ]… [ФАЙЛ]…
Команда также может быть использована в составе конвейеров (пайпов). Например
ls -l | sort [ОПЦИЯ]
Опции
У команды множество опций, вот наиболее важные и распространенные из них:
-b, —ignore-leading-blanks игнорировать пробелы в начале
-d, —dictionary-order рассматривать только пробелы, буквы и цифры
-g, —general-numeric-sort сравнивать в соответствии с числовыми значениями (строки преобразуются в числовой формат)
-i, —ignore-nonprinting не учитывать непечатаемые символы
-M, —month-sort сравнивать по месяцам в соответствии со следующим правилом [Любое неизвестное значение]< `JAN’ < … < `DEC’.
-h, —human-numeric-sort сравнивать числа, записанные в читаемом человеком формате (например, «2K», «1G»).
-n, —numeric-sort сравнивать числовые значения строк без преобразования в числовой формат
-R, —random-sort случайная сортировка
-r, —reverse вывод результатов в обратном порядке -o ФАЙЛ вывод результатов в указанный файл -k ПОЛЕ1, [ПОЛЕ2, ПОЛЕ3…] – сортировка по полям в заданном порядке
-u, —unique – удалять дублирующие записи в результатах сортировки
-c – проверка сортировки
Сортировка по алфавиту
Создадим файл data.txt со следующими строками: «апельсины яблоки бананы груши сливы».
echo -e "апельсины\nяблоки\nбананы\nгруши\nсливы" > data.txt
Здесь мы использовали обычную функцию перенаправления вывода команды echo в файл. Посмотрим файл с помощью команды cat.
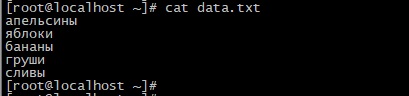
Как видим, сейчас строки выводятся в том же порядке как и были записаны. Для его сортировки в алфавитном порядке выполните команду:
sort data.txt
Вы получите следующий результат:
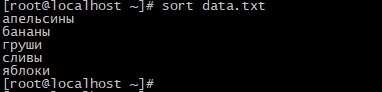
Как видим сейчас строки отсортированы в алфавитном порядке.
Вывод результатов в файл
Команда sort не изменяет исходный файл, а просто выводит его содержимое в отсортированном виде. Чтобы сохранить результаты сортировки, воспользуйтесь опцией -o или перенаправлением вывода:
sort -o output.txt data.txt sort data.txt > output.txt
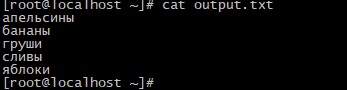
Выведем файл output.txt:
cat output.txt
Вывод результатов в обратном порядке
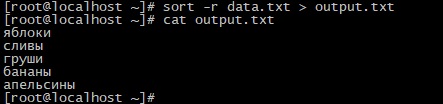
Опция -r позволяет выводить результаты сортировки в обратном порядке:
sort -r data.txt > output.txt cat output.txt
Сортировка по заданным полям
Для сортировки по определенным полям используется опция –k. Она указывается в следующем формате:
-k ПОЛЕ1, [ПОЛЕ2…]
Где ПОЛЕ1 и т.д. – номер поля (столбца), по которому осуществляется сортировка. Для примера создадим новый файл prices.txt со следующим содержимым:
апельсины 80 бананы 60 груши 150 сливы 200 яблоки 50
Для его сортировки по второму столбцу можно выполнить следующую команду:
sort -k 2 prices.txt
Результат будет следующим
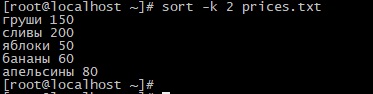
На первый взгляд кажется что команда сработала неправильно. Действительно, кажется что в самом верху должны стоять сливы, а яблоки нижней строкой, да и апельсины дороже банан. Но на самом деле команда sort воспринимает цифры не как число, а как строку, т.е сортировка происходит по первой цифре. Вот тогда все встает на свои места команда вывела последовательность не числовую сортировку «200-150-80-60-50» а строковую «1-2-5-6-8».
Опцию -k можно задавать в более сложном виде. Каждое поле задается в виде X.Y, где X – номер поля, а Y – начальная позиция поля, с которой начинается сортировка. Для примера создадим файл employee.txt со следующим содержимым:
01 Василий ст.программист 02 Иван мл.программист 03 Сергей ст.менеджер 04 Александр мл.менеджер
Если просто указать номер поля, результат сортировки будет следующим:
sort -k 3 employee.txt

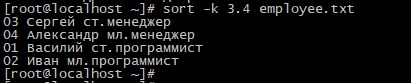
Значение начальной позиции сортировки 4 заставит команду игнорировать первые 3 буквы и начнет сортировку с 4-й, т.е после «ст.» и «мл.»
sort -k 3.4 employee.txt
Удаление дублирующих записей
Опция -u удаляет из результатов дублирующие записи и выводит только уникальные поля. Допустим, у нас есть файл cars.txt со следующими данными:
Mercedes Honda Mitsubishi Lexus Audi BMW Audi Lexus Lexus
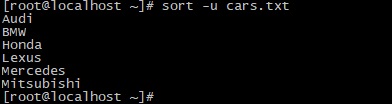
Команда
sort -u cars.txt
Выведет следующий результат:
Проверка сортировки
Опция -с позволяет проверить, отсортированы ли данные в файле. Если выполнение команды с этой опцией не возвращает никакого результата, значит, строки файла уже упорядочены. Иначе будут выведены строки, нарушающие порядок сортировки. Допустим, файл cars2.txt содержит следующие данные:
Audi
Cadillac
BMW
Dodge
Для проверки выполним следующую команду:
sort -c cars2.txt
Вот ее результат.
sort: cars2.txt:3: неправильный порядок: BMW
Мы видим, что строка «BMW» нарушает порядок сортировки:
Заключение
Команда sort – простой, но очень мощный и полезный при работе с данными инструмент. У нее есть множество разнообразных опций, помимо уже рассмотренных, которые можно узнать на соответствующей man-странице. Кроме того, ее можно использовать совместно с командами find и join для поиска по большому количеству файлов или объединения результатов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.