.Основным средством представления данных а также взаимодействия пользователя с системой в Linux является текст или текстовые данные. Как известно, управление операционной системой (ОС) Linux осуществляется, преимущественно, через терминал консоли командной оболочки, локальный или удалённый. Даже в самых современных дистрибутивах Linux, имеющими на борту удобные графические оболочки, всё же без использования командной оболочки не обойтись. Так уж сложилось исторически, поскольку создатели системы UNIX, чьим потомком является Linux, ещё на начальных этапах разработки системы старались всячески облегчить работу в командной оболочке и повысить «производительность труда» при работе с ней — ведь это напрямую связано с обработкой текстовых данных, начиная с ввода команд и редактирования файлов и заканчивая управлением потоками ввода/вывода.
В результате система совершенствовалась и дополнялась специализированными утилитами, которые способны ускорить, причём очень существенно, скорость и эффективность работы с текстовыми данными. Одной из таких утилит является awk — в общем случае текстовый фильтр для сортировки, выборки и даже программирования управления текстовыми данными. Благодаря таким инструментам и некоторым хитростям использования командной оболочки опытный пользователь способен без использования графических пользовательских интерфейсов (GUI) управлять системой и данными заметно быстрее и эффективнее нежели при задействовании всевозможных графических приложений.
Как работает awk?
На самом деле awk – это изначально язык программирования, предназначенный для обработки текста/данных. Поскольку, как уже отмечалось, в Linux-системах основной средой для взаимодействия между пользователем и машиной является текст, то обработка достаточно больших его объёмов вручную способна была парализовать на некоторое время процесс выполнения основной работы. Требовался инструмент для обеспечения автоматической обработки данных и позволяющий использовать эту возможность «на лету», т. е. прямо при работе в командной оболочке. Лучшим средством для достижения этой цели является использование специализированного языка программирования и регулярных выражений, которое реализовано в виде одноимённой утилиты — команды awk.
Справедливо заметить, что awk – это прежде всего Си-подобный язык программирования, но для удобства понимания, под awk принято понимать утилиту или команду. Разработчиками языка AWK являются Alfred V. Aho, Peter J. Weinberger и Brian W. Kernighan, по сокращённым инициалам которых язык и получил своё название. Создан язык в 1977 году. Кстати, на основе AWK когда-то был создан язык Perl, который и по сей день является одним из самых мощных языков для высокопроизводительной обработки данных.
В качестве исходных данных awk принимает на вход строку и после её обработки в зависимости от конкретных опций выдаёт результат. Исходные данные могут поступать из файла или из вывода другой команды/программы. Самым распространённым случаем использования awk является выборка определённых столбцов из результата вывода других команд, например:
$ ll | awk '{print $9}'
В результате вывод будет примерно таким:

Следует напомнить, что по-умолчанию вывод команды ll выглядит следующим образом:
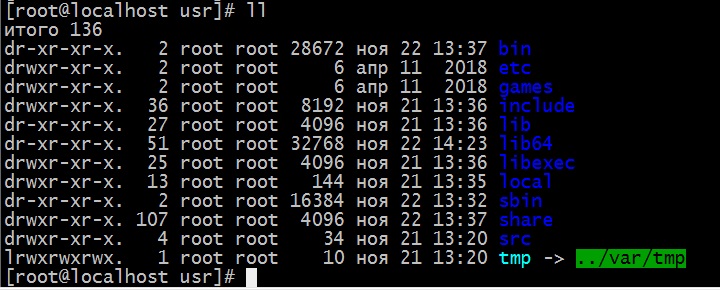
Как видно, команда awk помогла вывести только отдельный столбец из общего вывода ll – с именами каталогов и файлов.
Конечно, для решения подобных задач существует утилита grep, но awk гораздо быстрее и производительнее для обработки больших и сложных массивов данных.
Синтаксис
Для awk существуют понятия команды и действий, выполняемых этой командой. Действия, которые необходимо выполнить, заключаются в фигурные скобки {}, а сама команда (в которую и входят действия) содержится в одинарных кавычках ‘ ‘:
awk '{action1;action2;actionN}'
Несколько действий разделяются (в соответствии с семантикой языка AWK) символом точки с запятой.
Следующая команда выведет весь файл file.txt подобно команде cat
awk '{print}' file.txt
Вывод строки содержащую ‘string’
awk '/'string'/{print}' file.txt
Оператор print принимает выражения $0, $1, $2… Эти выражения указывают какие поля следует выводить, например. Оператор $0 выведет весь файл. Например
awk '{print $0}' file.txt
Аналогично awk ‘{print}’ file.txt выведет весь файл
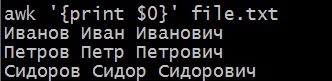
Если нам нужно получить только первый столбец
awk '{print $1}' file.txt
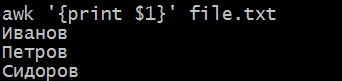
Второй awk ‘{print $2}’ file.txt и т.д.
Следующие примеры демонстрируют использование awk в самых распространённых ситуациях:
$ dpkg -l | awk '{print $2}'
В результате будет выведен список с именами установленных пакетов. Если же нужно узнать, к примеру, какие пакеты PHP или Apache установлены в системе. Следует дать команду:
$ dpkg -l | awk '/'php'/{print $2}'
или для Apache:
$ dpkg -l | awk '/'apache'/{print $2}'
Выражение для поиска/сортировки/отбора заключается, как можно видеть, между символами /’ ‘/.
Примеры использования awk
Для лучшего понимания стоит рассмотреть некоторые примеры использования утилиты awk. Для вывода/печати конкретных (например, второго и четвёртого) столбцов:
awk '{print $1,$3}'
Вывести все столбцы:
awk '{print $0}'
Вывод элементов третьего столбца, в наименовании которых содержится паттерн /’pattern’/:
awk ' /'pattern'/ {print $2} '
Напечатать количество строк в файле:
awk 'END { print NR }' targetfile
где NR – Number of Rows, т. е. количество строк. Для задания регулярных выражений:
awk '$1 ~/P/' targetfile
Здесь отбору подлежат все пункты в первом столбце, имена которых начинаются на «P».
awk '$1 ~!/P/' targetfile
Здесь обратное условие, определяемое символом «!», т. е. выбраны будут все пункты из первого столбца и имена которых не начинаются на «P».
Следующая команда выводит количество байтов всех файлов, которые последний раз изменялись в октябре:
ls -l | awk '$6 == "окт." { sum += $5 } END { print sum }'
По умолчанию в качестве разделителя используется пробел или табуляция. Для того что бы задать свой разделитель нужно использовать ключ «-F». Например для получения списка всех пользователей системы выполните команду
awk -F":" '{ print $1 }' /etc/passwd

Если бы мы запустили утилиту без указания разделителя, то вывод был бы таким
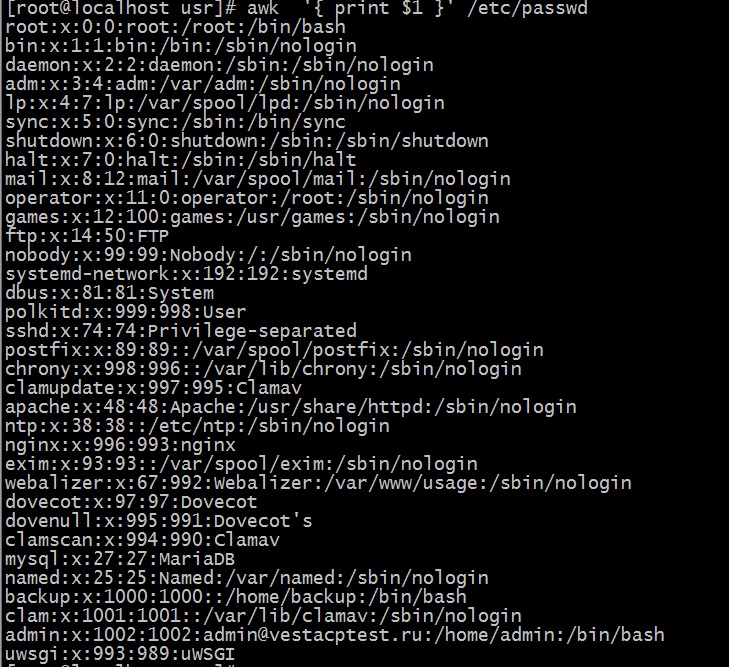
Конечно же, в приведённых примерах демонстрируются далеко не все возможности awk. Однако для эффективной работы в командной оболочке Linux, да и вообще с системой вышеприведённых примеров вполне достаточно. Поскольку они показывают общие принципы построения команд и действий для awk. Что позволяет создавать конкретные и более сложные конструкции в зависимости от конкретной задачи. Для более глубокого и масштабного использования утилиты awk. Рекомендуется посвятить некоторое время на изучения самого языка AWK.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.